Duplicate content generally refers to substantial blocks of text that are either the same or very similar, either across the internet or on the same domain.
While you won’t end up with a penalty as a result of your content duplication, you will find that it can significantly impact your search rankings in Google.
On top of this, when it comes to dealing with content duplication, there are so many steps that you can take that to help with the situation that it becomes difficult to know which one to choose! So as a leading digital marketing agency, we’re breaking down the steps to take when dealing with content duplication, what you should and shouldn’t do depending on the situation and how you can fix it!
Why You Need To Deal With Content Duplication
Understanding the reason why you need to deal with content duplication can influence which option you use in order to handle your situation.
For search engines, duplicate content can present a number of issues including:
- Not knowing which version of the content they should include within its index
- Knowing whether to push trust and authority through to one URL or split it between multiple
- And which version to rank for what keywords!
For site owners, websites can suffer with rankings and traffic losses.
Why does duplicate content happen?
In most cases, content duplication can actually happen by complete accident. It is suggested that up to 29% of content on the internet is duplicate content and even way back in 2013, Matt Cutts posted a video suggesting that between 25% to 30% of the content is duplicative.
But how can you accidentally cause duplicate content? It’s actually pretty easy to do, which is probably why there is so much:
URL Variations
URL parameters are a common cause for duplicate content issues, particularly on eCommerce websites. Some examples of URL variations include:
- Click tracking and analytics codes – these can often cause URL variations and parameters, which can lead to a whole bunch of technical SEO issues, as well as content duplication.
- Session IDs – also a leading cause of a number of URL variations and ultimately duplicate content, and this is one of the more common causes.
- Printer-friendly versions – these can be readily indexed if you’re not careful!
But tracking and URL variations aren’t the only cause.
HTTP / HTTPs or WWW / non-WWW
There are many scenarios where HTTP / HTTPS and non-www / WWW. Versions have not been effectively redirected. This means that ultimately the same content lives on both versions of the site, and therefore both versions of the site are attempting to be indexed at the same time on the same search engine.
Scraped Content / Boilerplate Content
Some websites on the internet exist solely with duplicate content which they have scraped from other websites. Alternatively, and mostly in the case of eCommerce website, product descriptions or other small types of text are sourced directly from the manufacturer websites or documentation which then every other eCommerce website selling the same products also has on their website. This is one of the main reasons why content duplication can occur on the internet and it can significantly harm your rankings.
How To Fix Your Duplicate Content Issues
In order to find out the best techniques that the industry use for fixing their duplicate content issues, I put a poll out on Twitter and LinkedIn. And the results were interesting.
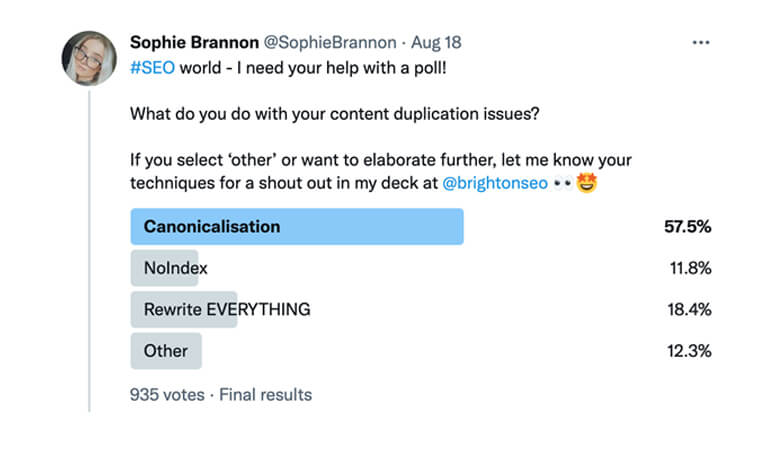
The majority of votes, over 50%!, opted for ‘canonicalisation’. But it was the 12.3% who voted ‘other’ where the really interesting opinions occurred.
Now, many of the ‘other’ votes were focused around properly diagnosing the issue before coming up with a solution which is the right approach to anything in SEO – find the cause to find the fix.
But alongside this, there were a few examples of other types of content duplication which are not quite as commonly known of or dealt with.
Andy Beard had some really useful insights here:
Handling affiliate links
Affiliate links often appear indexed, but don’t actually receive traffic. I have also seen affiliate links rank first for a brand name (not just 302 hijacked) So if there is an issue, dynamic noindex, channel through robots.txt or use anchors
Shopping Carts
Pages inside shopping carts are generally very bad landing pages, often without any navigation out. You really don’t want them index most of the time so almost 100% noindex rather than trying to fix titles etc.
Highly Scaled Duplicate Content
It is possible to have highly scaled largely duplicate content that still ranks top 3 and gets traffic. Sure, it would be better to make it more unique but that might cost you 5-10x initial implementation cost.
But how exactly do you fix all of these things?
Once you’ve diagnosed the type of issue, you can break down the fix. The examples given below do need to be assessed on a case by case basis, not a general rule of thumb, but these are some of the most common fixes:
Canonicalisation
Canonicalisation allows you to specify to Google which page is the standard form of the page and the one that should be indexed. By adding rel=canonical and pointing this to the page that is of most value to you can allow you to indicate to Google which one you would prefer to be crawled, indexed and is of the highest weighting in your eyes.
It is important to remember that a canonical tag is a hint not a directive, and therefore Google can disregard this. There have been many occasions where Google has completely ignored the canonical tag or added its own one, which you can view directly in Google Search Console when inspecting the URL.
Many individuals will also, by default, choose a canonical tag as the simplest solution as it can be adjusted within the HTML / source code of the page. However simple is not always better. I’ve seen numerous cases where a page is canonicalised to another when the content is not exactly duplicate, but is similar or around a similar topic. It is in these instances that Google may disregard the canonical and one of the next few options may be of better use.
Content Rewrites
Rewriting content is a highly useful solution, if you have the resource and budget to be able to work through these pages. With a large number of duplicate content issues deriving from eCommerce websites, particularly those who use other competitors or trade websites for their product description copy (and yes I’m talking about a simple copy & paste situation which occurs more often than you may think), resource can often be a big deciding factor in the solution.
However, content rewrites are often only suitable in one or more of the following scenarios:
- You are able to target different keywords within the copy
- You are able to target a different search intent
- You can effectively refocus the content
- You can consolidate two or more pages on a similar topic
If your content is taken from another source, then you will not necessarily be penalised for this, but you may find that your product descriptions do not rank anywhere in SERPs – simply because Google understands that your competitor / the trade website / the original source of the copy did publish it first.
Remove & Redirect
If the content is a genuine mistake, it happens, then your best option may be to completely remove and redirect. Implement a 301 redirect within your htaccess file or administrative console depending on if you’re using Apache or IIS. Another reason why individuals may opt for a canonical over a redirect solution however is as a result of technical / access restrictions – for example access which does not allow the implementation of redirects in either the CMS or the htaccess. This can sometimes be the case of bespoke CMS or those of large corporations which are built using niche platforms.
Internal Linking
This may seem like a strange one when looking at content duplication, but this is all about site hierarchy and consistency. There are some circumstances where CMS’ will automatically create a new page when an internal link is inconsistent (I have seen this recently on OpenCart CMS).
For example, if you are adding internal links such as the below, then you may end up with the same page being created twice with different URL structure.
https://www.example.com/page/
https://www.example.com/page
https://www.example.com/page/index.html
Keeping this internal linking consistent will allow you to ensure there’s minimal human error causing duplication on the site.
Country Specific Content
For country specific content, then it is advised in Google’s guidelines to use top level domains to help the search engine to serve the most appropriate content. This is because it is far clearer to Google that a site’s content is say Spanish focused when looking at https://www.example.es than https://www.example.es/es/ or https://es.example.com. This does not, however, mean that subfolders or subcategory approaches to international SEO are advised against, as there are pros and cons for each set up.
Content Spinning For Duplicate Product Descriptions
Something that is being used a lot more recently in SEO not just for this purpose but for general content automation is the use of OpenAI GPT-3 to help generate content at scale. There are some restrictions with this of course, with AI not being perfect as we can see with Google’s latest title tag fiasco, and the fact that a number of content spinner tools on the web are in negotiation with OpenAI on the ability to bulk upload so you may need to code something pretty special to help with this at scale, however this is certainly an option to help produce content and in particular product descriptions that’s not an exact copy of every other website selling the same product.
Summary
As with anything in SEO and tech, ensuring you understand the root cause of the problem can help to attribute the most appropriate solution for your type of content duplication. While many SEO’s tend to use a blanket approach with canonicalization, there may be circumstances where another solution would be more beneficial for your SEO performance and site visibility, particularly where there is opportunity to produce fresh, optimised and focused content.
CEO & Founder
Ben founded Absolute Digital Media, an award-winning digital marketing agency, as an entrepreneur in 2008.
 Contact Us
Contact Us
